Motivation & Contribution

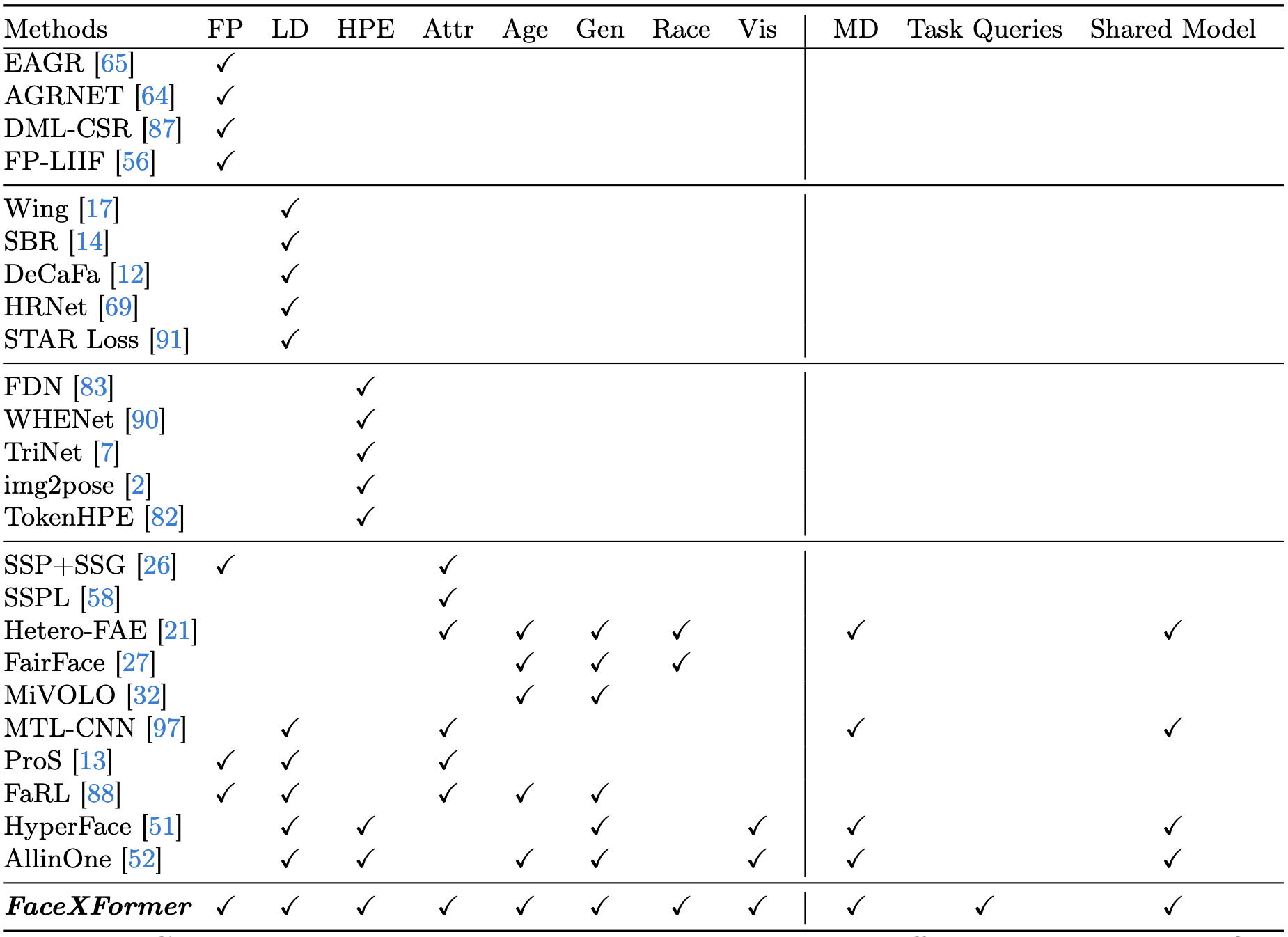
Comparison with representative methods under different task settings. FaceXformer can perform various facial analysis tasks in single model. FP - Face Parsing, LD - Landmarks Detection, HPE - Head Pose Estimation, Attr - At- tributes Recognition, Age - Age Estimatin, Gen - Gender Estimation, Race - Race Estimation, Vis - Landmarks Visibility Prediction, MD - Multi-dataset Training
- In recent years, significant advancements have been made in facial analysis, developing state-of-the-art methods for various tasks. Despite these methods achieving promising performance, they cannot be integrated into a single pipeline due to their specialized model designs and task-specific pre-processing techniques.
- FaceXformer is an end-to-end unified model capable of handling a comprehensive range of facial analysis tasks such as face parsing, landmark detection, head pose estimation, attributes recognition, and estimation of age, gender, race, and landmarks visibility.
- It leverages a transformer-based encoder-decoder architecture where each task is treated as a learnable token, enabling the integration of multiple tasks within a single framework.
- It effectively handles images "in-the-wild," demonstrating its robustness and generalizability across eight heterogenous tasks, all while maintaining the real-time performance of 37 FPS.
FaceXformer Framework
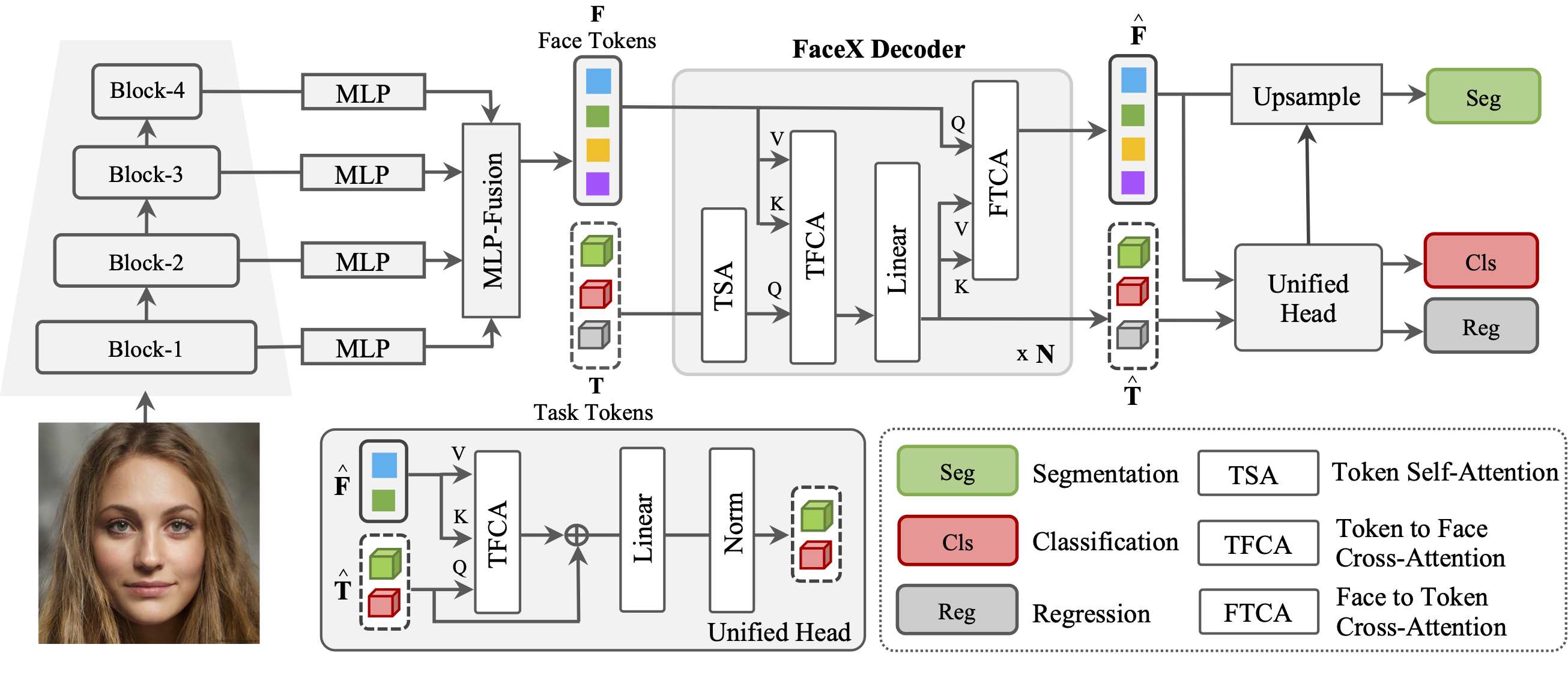 Overview of FaceXformer framework. It employs an encoder-decoder
architecture, extracting multi-scale features from the input face image I, and
fusing them into a unified representation F via MLP-Fusion. Task tokens T
are processed alongside face representation F in the decoder, resulting in
refined
task-specific tokens
T
^
. These refined tokens are then used for
task-specific predictions by passing through the unified head.
Overview of FaceXformer framework. It employs an encoder-decoder
architecture, extracting multi-scale features from the input face image I, and
fusing them into a unified representation F via MLP-Fusion. Task tokens T
are processed alongside face representation F in the decoder, resulting in
refined
task-specific tokens
T
^
. These refined tokens are then used for
task-specific predictions by passing through the unified head.
Quantitative Results
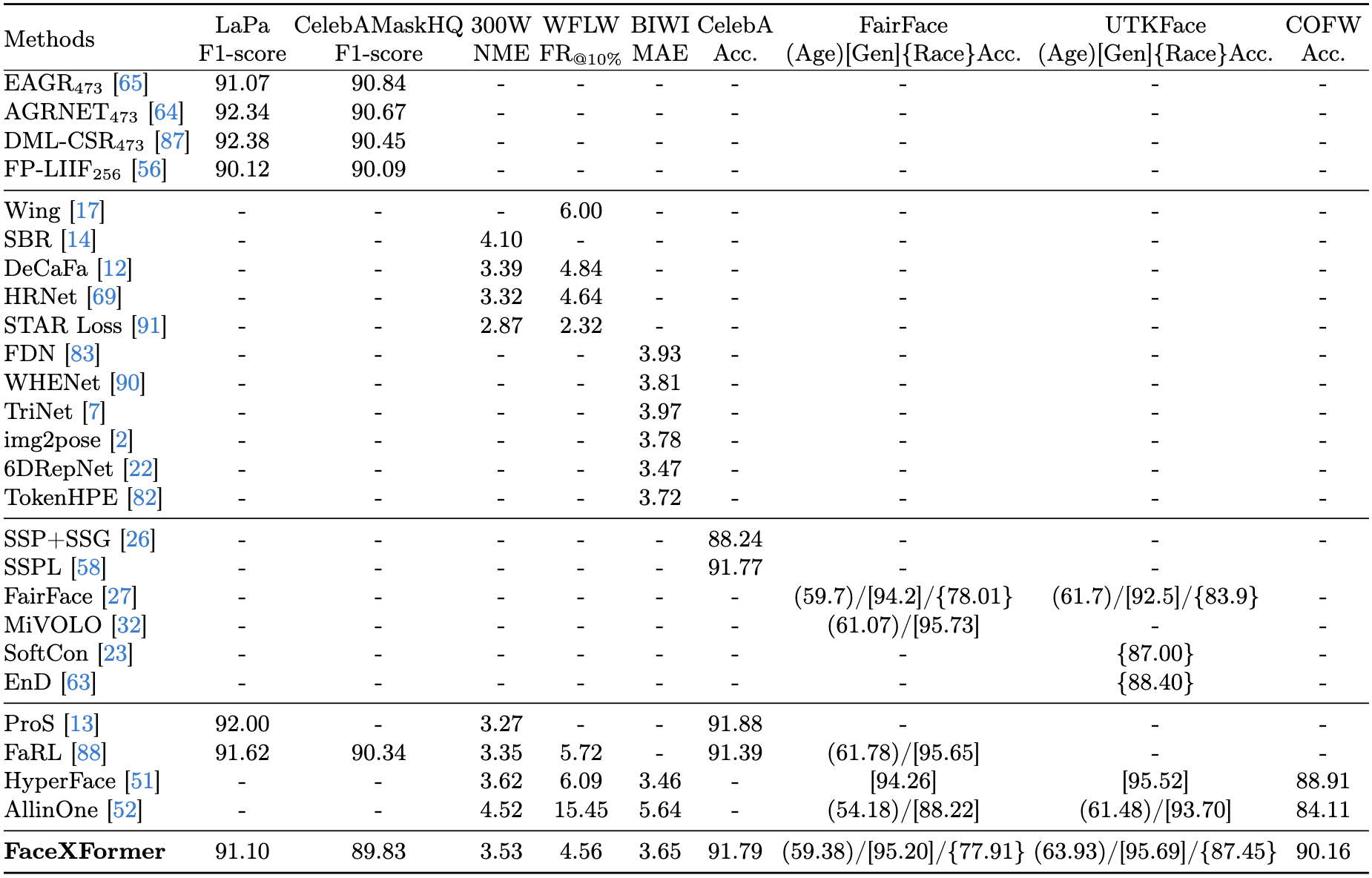
Comparison with specialized models and existing multi-task networks.
Qualitative Results
 Qualitative comparison of FaceXformer against other multi-task models
Qualitative comparison of FaceXformer against other multi-task models
 Visualization of "in-the-wild" images queried for multiple task tokens. Attributes
represent the 40 binary attributes defined in the CelebA dataset, indicating the
presence (1) or absence (0) of specific facial attributes
Visualization of "in-the-wild" images queried for multiple task tokens. Attributes
represent the 40 binary attributes defined in the CelebA dataset, indicating the
presence (1) or absence (0) of specific facial attributes
BibTeX
@article{narayan2024facexformer,
title={FaceXFormer: A Unified Transformer for Facial Analysis},
author={Narayan, Kartik and VS, Vibashan and Chellappa, Rama and Patel, Vishal M},
journal={arXiv preprint arXiv:2403.12960},
year={2024}
}