Motivation and Contributions
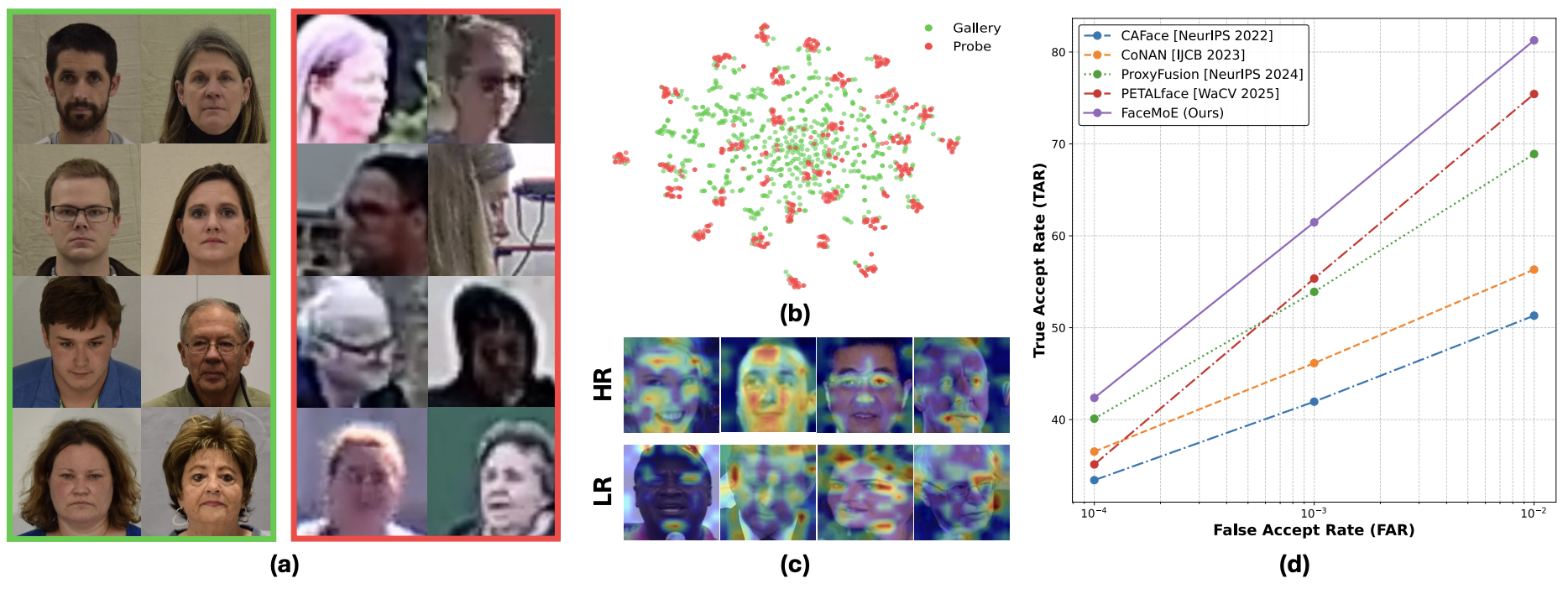
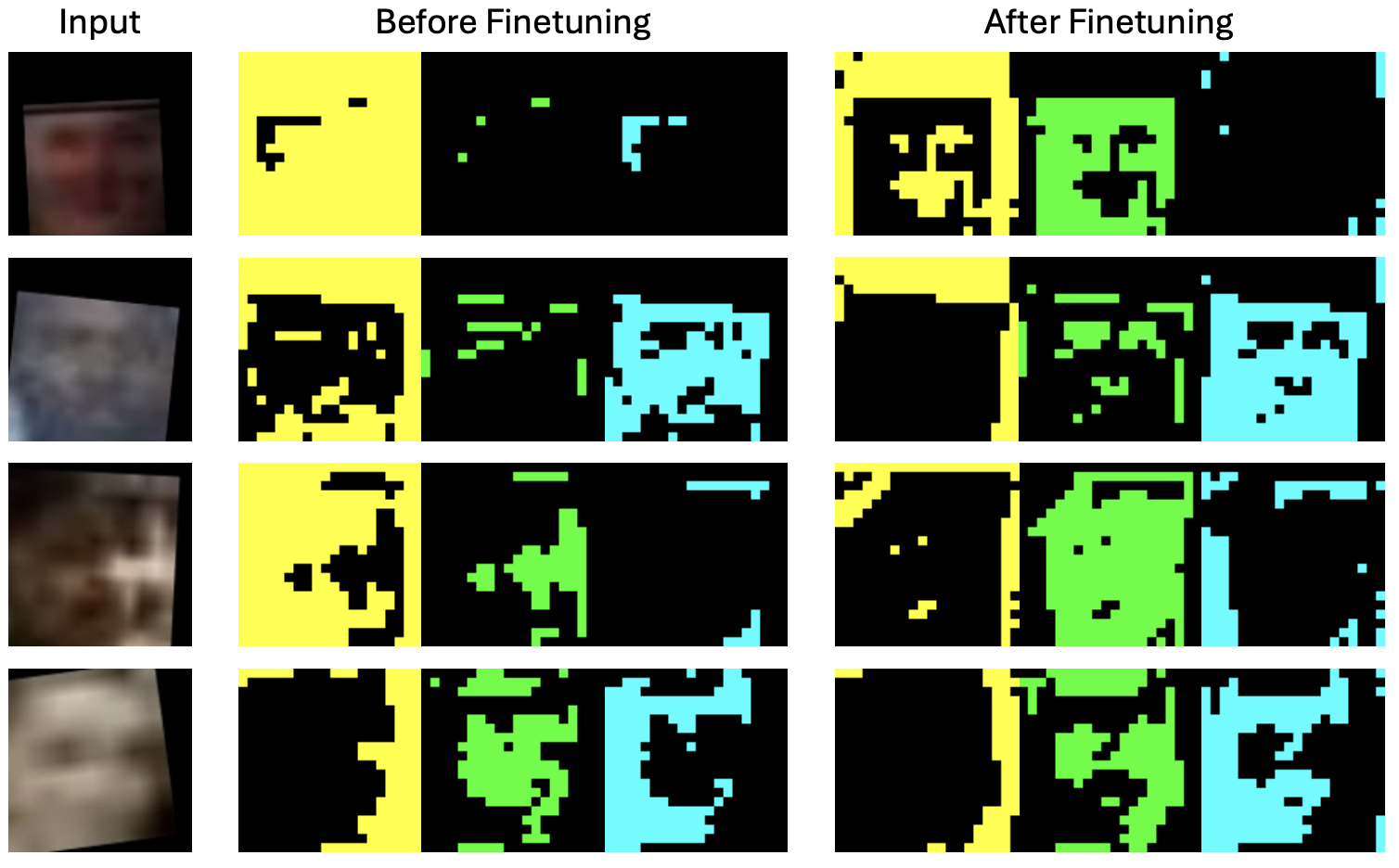
The figure highlights the central low-resolution face recognition challenges that motivate FaceMoE: (1) severe degradation in probe frames causes weak and unstable identity cues, making reliable feature aggregation difficult; (2) a strong domain gap exists between high-resolution gallery images and low-resolution probe images, where models rely on different facial cues across resolutions; and (3) naive fine-tuning on low-resolution data can trigger catastrophic forgetting and reduce pretrained performance on high-quality data.
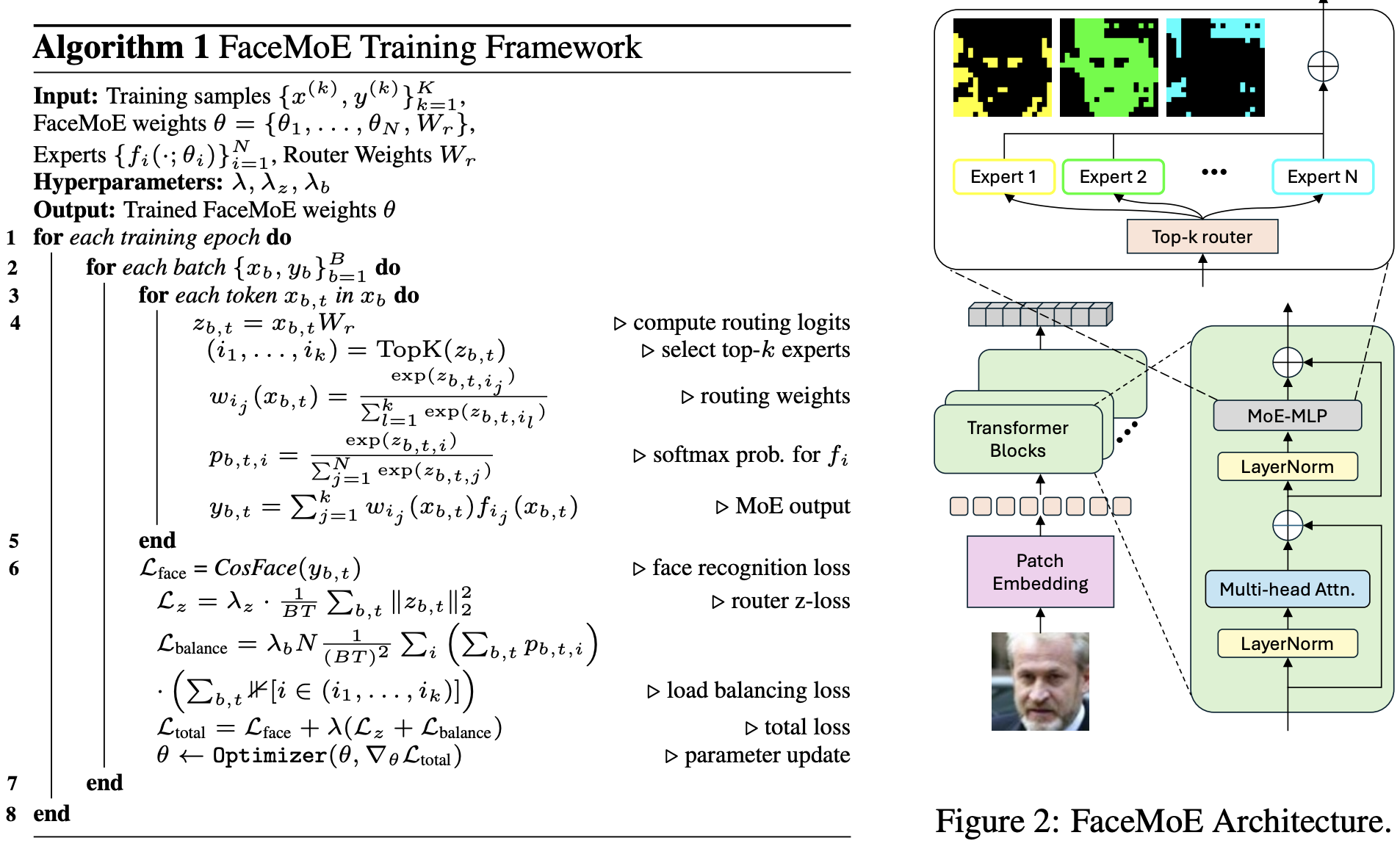
- FaceMoE introduces sparse FFN experts in transformer blocks to improve feature extraction for degraded low-resolution probes.
- A top-k router assigns tokens to specialized experts, enabling resolution-aware routing across facial regions.
- Modular sparse activation supports adaptation to low-resolution datasets while reducing catastrophic forgetting.
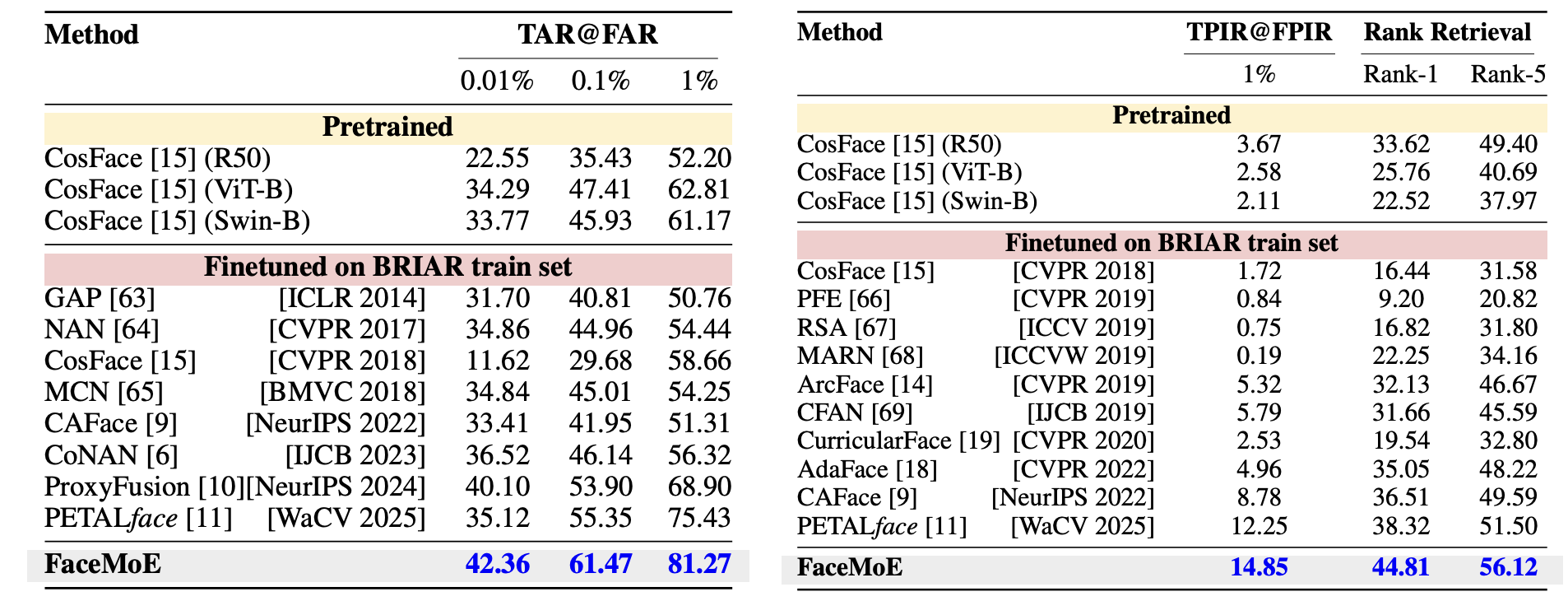
- These design choices lead to strong low-resolution recognition gains with minimal drop on high-quality and mixed-quality benchmarks.